Scholarship
Recent Work
AIPP meets weekly throughout the year to workshop scholarship at various stages of development. We highlight some of our recent, publically-available work below.
Despite growing calls for participation in AI design, there are to date few empirical studies of what these processes look like and how they can be structured for meaningful engagement with domain experts. In this paper, we examine a notable yet understudied AI design process in the legal domain that took place over a decade ago, the impact of which still informs legal automation efforts today. Specifically, we examine the design and evaluation activities that took place from 2006 to 2011 within the Text REtrieval Conference’s (TREC) Legal Track, a computational research venue hosted by the National Institute of Standards and Technologies. The Legal Track of TREC is notable in the history of AI research and practice because it relied on a range of participatory approaches to facilitate the design and evaluation of new computational techniques-in this case, for automating attorney document review for civil litigation matters. Drawing on archival research and interviews with coordinators of the Legal Track of TREC, our analysis reveals how an interactive simulation methodology allowed computer scientists and lawyers to become co-designers and helped bridge the chasm between computational research and real-world, high-stakes litigation practice. In analyzing this case from the recent past, our aim is to empirically ground contemporary critiques of AI development and evaluation and the calls for greater participation as a means to address them.
Fernando Delgado, Solon Barocas, and Karen Levy
Proc. ACM Hum.-Comput. Interact. 6, CSCW1, Article 51 (April 2022)
In 1996, Accountability in a Computerized Society issued a clarion call concerning the erosion of accountability in society due to the ubiquitous delegation of consequential functions to computerized systems. Nissenbaum described four barriers to accountability that computerization presented, which we revisit in relation to the ascendance of data-driven algorithmic systems–i.e., machine learning or artificial intelligence–to uncover new challenges for accountability that these systems present. Nissenbaum’s original paper grounded discussion of the barriers in moral philosophy; we bring this analysis together with recent scholarship on relational accountability frameworks and discuss how the barriers present difficulties for instantiating a unified moral, relational framework in practice for data-driven algorithmic systems. We conclude by discussing ways of weakening the barriers in order to do so.
A. Feder Cooper, Emanuel Moss, Benjamin Laufer, and Helen Nissenbaum
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)

Algorithms provide powerful tools for detecting and dissecting human bias and error. Here, we develop machine learning methods to to analyze how humans err in a particular high-stakes task: image interpretation. We leverage a unique dataset of 16,135,392 human predictions of whether a neighborhood voted for Donald Trump or Joe Biden in the 2020 US election, based on a Google Street View image. We show that by training a machine learning estimator of the Bayes optimal decision for each image, we can provide an actionable decomposition of human error into bias, variance, and noise terms, and further identify specific features (like pickup trucks) which lead humans astray. Our methods can be applied to ensure that human-in-the-loop decision-making is accurate and fair and are also applicable to black-box algorithmic systems.
J.D. Zamfirescu-Pereira, Jerry Chen, Emily Wen, Allison Koenecke, Nikhil Garg, and Emma Pierson
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Oral Presentation
In many real-world situations, data is distributed across multiple locations and can’t be combined for training. Federated learning is a novel distributed learning approach that allows multiple federating agents to jointly learn a model. While this approach might reduce the error each agent experiences, it also raises questions of fairness: to what extent can the error experienced by one agent be significantly lower than the error experienced by another agent? In this work, we consider two notions of fairness that each may be appropriate in different circumstances: egalitarian fairness (which aims to bound how dissimilar error rates can be) and proportional fairness (which aims to reward players for contributing more data). For egalitarian fairness, we obtain a tight multiplicative bound on how widely error rates can diverge between agents federating together. For proportional fairness, we show that sub-proportional error (relative to the number of data points contributed) is guaranteed for any individually rational federating coalition.
Kate Donahue and Jon Kleinberg
NeurIPS Workshop on Learning and Decision-making with Strategic Feedback
Best Paper Award
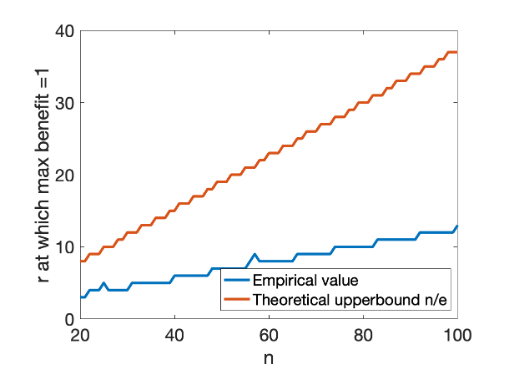
Many policies allocate harms or benefits that are uncertain in nature: they produce distributions over the population in which individuals have different probabilities of incurring harm or benefit. Comparing different policies thus involves a comparison of their corresponding probability distributions, and we observe that in many instances the policies selected in practice are hard to explain by preferences based only on the expected value of the total harm or benefit they produce. In cases where the expected value analysis is not a sufficient explanatory framework, what would be a reasonable model for societal preferences over these distributions? Here we investigate explanations based on the framework of probability weighting from the behavioral sciences, which over several decades has identified systematic biases in how people perceive probabilities. We show that probability weighting can be used to make predictions about preferences over probabilistic distributions of harm and benefit that function quite differently from expected-value analysis, and in a number of cases provide potential explanations for policy preferences that appear hard to motivate by other means. In particular, we identify optimal policies for minimizing perceived total harm and maximizing perceived total benefit that take the distorting effects of probability weighting into account, and we discuss a number of real-world policies that resemble such allocational strategies. Our analysis does not provide specific recommendations for policy choices, but is instead fundamentally interpretive in nature, seeking to describe observed phenomena in policy choices.
Hoda Heidari, Solon Barocas, Jon Kleinberg, and Karen Levy
Proc. 2021 ACM Conference on Economics and Computation (EC 2021)
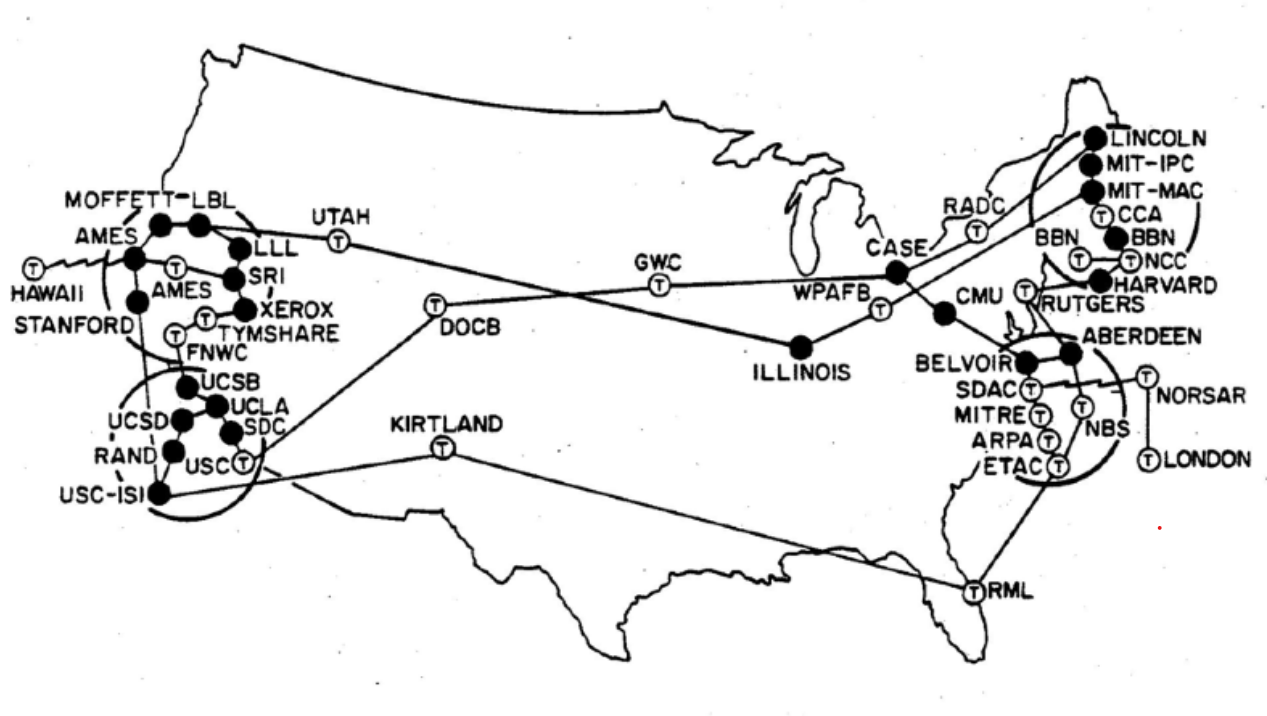
Contemporary concerns over the governance of technological systems often run up against narratives about the technical infeasibility of designing mechanisms for accountability. While in recent AI ethics literature these concerns have been deliberated predominantly in relation to ML, other instances in computing history also presented circumstances in which computer scientists needed to un-muddle what it means to design accountable systems. One such compelling narrative can be found in canonical histories of the Internet that highlight how its original designers’ commitment to the “End-to-End” architectural principle precluded other features from being implemented, resulting in the fast-growing, generative, but ultimately unaccountable network we have today. This paper offers a critique of such technologically essentialist notions of accountability and the characterization of the “unaccountable Internet” as an unintended consequence. It explores the changing meaning of accounting and its relationship to accountability in a selected corpus of requests for comments (RFCs) concerning the early Internet’s design from the 1970s and 80s. We characterize four ways of conceptualizing accounting: as billing, as measurement, as management, and as policy, and demonstrate how an understanding of accountability was constituted through these shifting meanings. We link together the administrative and technical mechanisms of accounting for shared resources in a distributed system and an emerging notion of accountability as a social, political, and technical category, arguing that the former is constitutive of the latter. Recovering this history is not only important for understanding the processes that shaped the Internet, but also serves as a starting point for unpacking the complicated political choices that are involved in designing accountability mechanisms for other technological systems today.
A. Feder Cooper and Gili Vidan
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)

Labor-saving technology has already decreased employment opportunities for middle-skill workers. Experts anticipate that advances in AI and robotics will cause even more significant disruptions in the labor market over the next two decades. This paper presents three experimental studies that investigate how this profound economic change could affect mass politics. Recent observational studies suggest that workers’ exposure to automation risk predicts their support not only for redistribution but also for right-wing populist policies and candidates. Other observational studies, including my own, find that workers underestimate the impact of automation on their job security. Misdirected blame towards immigrants and workers in foreign countries, rather than concerns about workplace automation, could be driving support for right-wing populism. To correct American workers’ beliefs about the threats to their jobs, I conducted three survey experiments in which I informed workers about the existent and future impact of workplace automation. While these informational treatments convinced workers that automation threatens American jobs, they failed to change respondents’ preferences on welfare, immigration, and trade policies. My research finds that raising awareness about workplace automation did not decrease opposition to globalization or increase support for policies that will prepare workers for future technological disruptions.
Baobao Zhang
Proc. 5th AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES 2022)
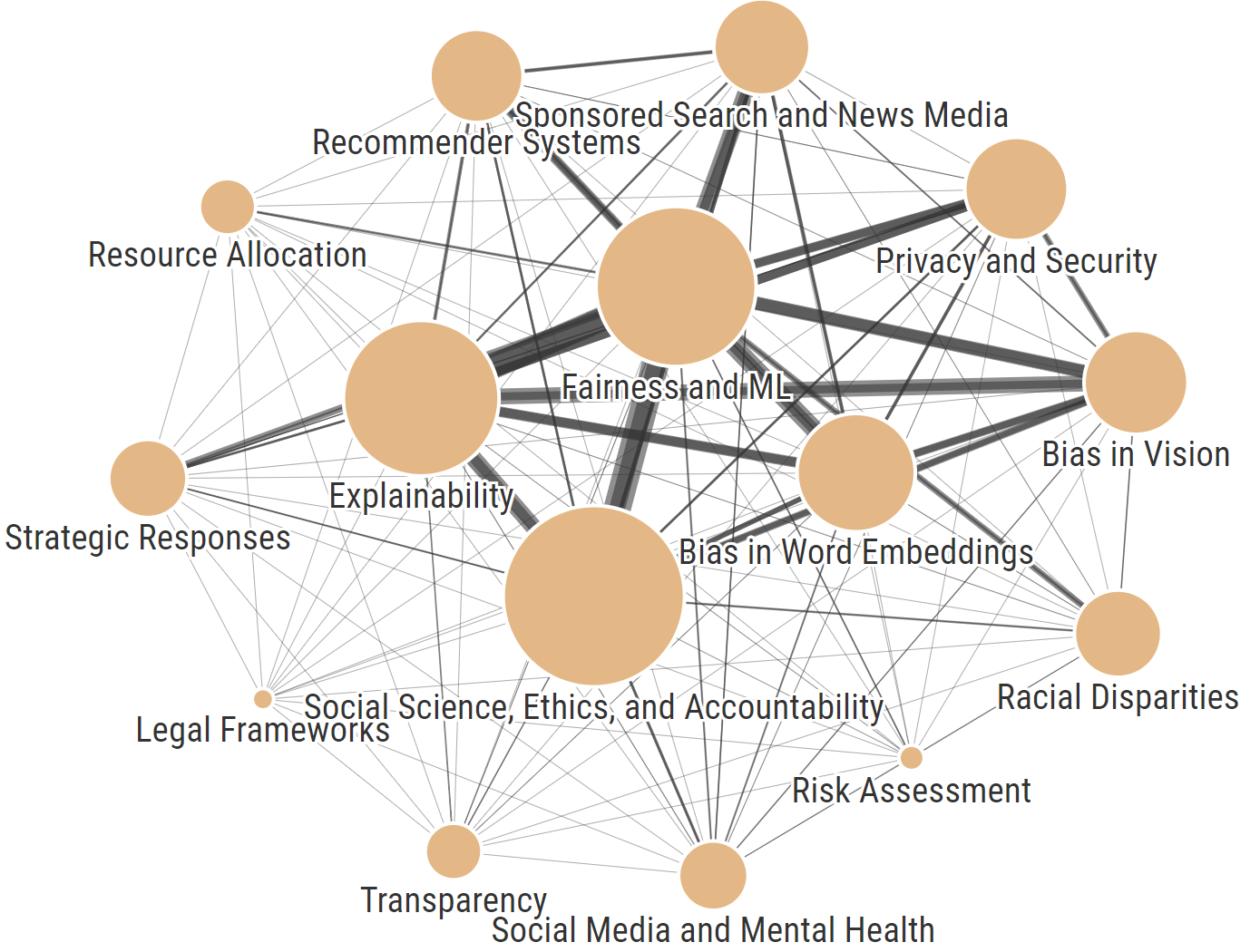
Fairness, Accountability, and Transparency (FAccT) for socio-technical systems has been a thriving area of research in recent years. An ACM conference bearing the same name has been the central venue for scholars in this area to come together, provide peer feedback to one another, and publish their work. This reflexive study aims to shed light on FAccT’s activities to date and identify major gaps and opportunities for translating contributions into broader positive impact. To this end, we utilize a mixed-methods research design. On the qualitative front, we develop a protocol for reviewing and coding prior FAccT papers, tracing their distribution of topics, methods, datasets, and disciplinary roots. We also design and administer a questionnaire to reflect the voices of FAccT community members and affiliates on a wide range of topics. On the quantitative front, we use the full text and citation network associated with prior FAccT publications to provide further evidence about topics and values represented in FAccT. We organize the findings from our analysis into four main dimensions: the themes present in FAccT scholarship, the values that underpin the work, the impact of the contributions both within academic circles and beyond, and the practices and informal norms of the community that has formed around FAccT. Finally, our work identifies several suggestions on directions for change, as voiced by community members.
Benjamin Laufer, Sameer Jain, A. Feder Cooper, Jon Kleinberg, and Hoda Heidari
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Recent scholarship has brought attention to the fact that there often exist multiple models for a given prediction task with equal accuracy that differ in their individual-level predictions or aggregate properties. This phenomenon—which we call model multiplicity—can introduce a good deal of flexibility into the model selection process, creating a range of exciting opportunities. By demonstrating that there are many different ways of making equally accurate predictions, multiplicity gives model developers the freedom to prioritize other values in their model selection process without having to abandon their commitment to maximizing accuracy. However, multiplicity also brings to light a concerning truth: model selection on the basis of accuracy alone—the default procedure in many deployment scenarios—fails to consider what might be meaningful differences between equally accurate models with respect to other criteria such as fairness, robustness, and interpretability. Unless these criteria are taken into account explicitly, developers might end up making unnecessary trade-offs or could even mask intentional discrimination. Furthermore, the prospect that there might exist another model of equal accuracy that flips a prediction for a particular individual may lead to a crisis in justifiability: why should an individual be subject to an adverse model outcome if there exists an equally accurate model that treats them more favorably? In this work, we investigate how to take advantage of the flexibility afforded by model multiplicity while addressing the concerns with justifiability that it might raise?
Emily Black, Manish Raghavan, and Solon Barocas
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Oral Presentation

“Algorithmic audits” have been embraced as tools to investigate the functioning and consequences of sociotechnical systems. Though the term is used somewhat loosely in the algorithmic context and encompasses a variety of methods, it maintains a close connection to audit studies in the social sciences—which have, for decades, used experimental methods to measure the prevalence of discrimination across domains like housing and employment. In the social sciences, audit studies originated in a strong tradition of social justice and participatory action, often involving collaboration between researchers and communities; but scholars have argued that, over time, social science audits have become somewhat distanced from these original goals and priorities. We draw from this history in order to highlight difficult tensions that have shaped the development of social science audits, and to assess their implications in the context of algorithmic auditing. In doing so, we put forth considerations to assist in the development of robust and engaged assessments of sociotechnical systems that draw from auditing’s roots in racial equity and social justice.
Briana Vecchione, Solon Barocas, and Karen Levy

Modern city governance relies heavily on crowdsourcing (or “co-production”) to identify problems such as downed trees and power-lines. A major concern in these systems is that residents do not report problems at the same rates, leading to an inequitable allocation of government resources. However, measuring such under-reporting is a difficult statistical task, as, almost by definition, we do not observe incidents that are not reported. Thus, distinguishing between low reporting rates and low ground-truth incident rates is challenging. We develop a method to identify (heterogeneous) reporting rates, without using external (proxy) ground truth data. Our insight is that rates on duplicate reports about the same incident can be leveraged, to turn the question into a standard Poisson rate estimation task – even though the full incident reporting interval is also unobserved. We apply our method to over 100,000 resident reports made to the New York City Department of Parks and Recreation, finding that there are substantial spatial and socio-economic disparities in reporting rates, even after controlling for incident characteristics.
Zhi Liu and Nikhil Garg
Proc. 2022 ACM Conference on Economics and Computation (EC 2022)
Contact tracing is a key tool for managing epidemic diseases like HIV, tuberculosis, and COVID-19. Manual investigations by human contact tracers remain a dominant way in which this is carried out. This process is limited by the number of contact tracers available, who are often overburdened during an outbreak or epidemic. As a result, a crucial decision in any contact tracing strategy is, given a set of contacts, which person should a tracer trace next? In this work, we develop a formal model that articulates these questions and provides a framework for comparing contact tracing strategies. Through analyzing our model, we give provably optimal prioritization policies via a clean connection to a tool from operations research called a “branching bandit”. Examining these policies gives qualitative insight into trade-offs in contact tracing applications.
M. Meister and J. Kleinberg
Poster at EAAMO 2022 Conference
Complete List
2022
Unfair Artificial Intelligence: How FTC Intervention Can Overcome the Limitations of Discrimination Law
Andrew Selbst and Solon Barocas
University of Pennsylvania Law Review, Vol. 171 (2023)
Mimetic Models: Ethical Implications of AI that Acts Like You
Reid McIlroy-Young, Ashton Anderson, Solon Barocas, Jon Kleinberg, and Siddhartha Sen
Proc. 5th AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES 2022)
Disentangling the Components of Ethical Research in Machine Learning
Carolyn Ashurst, Solon Barocas, Rosie Campbell, and Inioluwa Deborah Raji
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Model Multiplicity: Opportunities, Concerns, and Solutions
Emily Black, Manish Raghavan, and Solon Barocas
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Explanations in Whose Interests
Solon Barocas and Manish Raghavan
Workshop on Explainable AI in Finance (ICAIF 2021); Workshop on Explainable Agency in Artificial Intelligence (AAAI 2022)
Accountability in an Algorithmic Society: Relationality, Responsibility, and Robustness in Machine Learning
A. Feder Cooper, Emanuel Moss, Benjamin Laufer, and Helen Nissenbaum
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Making the Unaccountable Internet: The Changing Meaning of Accounting in the Design of the Early ARPANET
A. Feder Cooper and Gili Vidan
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Fast or Accurate? Governing Conflicting Goals in Highly Autonomous Vehicles
A. Feder Cooper and Karen Levy
20 Colorado Technology Law Journal 249 (2022)
Non-Determinism and the Lawlessness of Machine Learning Code
A. Feder Cooper, Jonathan Frankle, and Christopher De Sa
Proc. 2022 ACM Symposium on Computer Science and Law (CSLAW 2022)
Choices, Risks, and Reward Reports: Charting Public Policy for Reinforcement Learning Systems
Thomas Krendl Gilbert, Sarah Dean, Tom Zick, and Nathan Lambert
CLTC Whitepaper
Reward Reports for Reinforcement Learning
Thomas Krendl Gilbert, Sarah Dean, Nathan Lambert, Tom Zick, and Aaron Snoswell
Preprint
Preference Dynamics Under Personalized Recommendations
Sarah Dean and Jamie Morgenstern
EC 2022
Multi-learner risk reduction under endogenous participation dynamics
Sarah Dean, Mihaela Curmei, Lillian J. Ratliff, Jamie Morgenstern, and Maryam Fazel
Preprint
Engineering a Safer Recommender System
Liu Leqi and Sarah Dean
Responsible Decision Making in Dynamic Environments Workshop at ICML 2022
Modeling Content Creator Incentives on Algorithm-Curated Platforms
Jiri Hron, Karl Krauth, Michael I. Jordan, Niki Kilbertus, and Sarah Dean
Preprint
An Uncommon Task: Participatory Design in Legal AI
Fernando Delgado, Solon Barocas, and Karen Levy
Proc. ACM Hum.-Comput. Interact. 6, CSCW1, Article 51 (April 2022)
Human-Algorithm Collaboration: Achieving Complementarity and Avoiding Unfairness
Kate Donahue, Alexandra Chouldechova, and Krishnaram Kenthapadi
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Trucks Don’t Mean Trump: Diagnosing Human Error in Image Analysis
J.D. Zamfirescu-Pereira, Jerry Chen, Emily Wen, Allison Koenecke, Nikhil Garg, and Emma Pierson
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Equity in Resident Crowdsourcing: Measuring Under-reporting without Ground Truth Data
Zhi Liu and Nikhil Garg
Proc. 2022 ACM Conference on Economics and Computation (EC 2022)
The Challenge of Understanding What Users Want: Inconsistent Preferences and Engagement Optimization
J. Kleinberg, M. Raghavan, S. Mullainathan
Proc. 23rd ACM Conference on Economics and Computation (EC 2022)
On the Effect of Triadic Closure on Network Segregation
R. Abebe, N. Immorlica, J. Kleinberg, B. Lucier, A. Shirali
Proc. 23rd ACM Conference on Economics and Computation (EC 2022)
Learning Models of Individual Behavior in Chess
R. McIlroy-Young, R. Wang, S. Sen, J. Kleinberg, A. Anderson
Proc. 28th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining (KDD 2022)
Allocating Stimulus Checks in Times of Crisis
M. Papachristou, J. Kleinberg
Proc. 31st International World Wide Web Conference (WWW 2022)
Opinion Dynamics with Varying Susceptibility to Persuasion via Non-Convex Local Search
R. Abebe, T-H Chan, J. Kleinberg, Z. Liang, D. Parkes, M. Sozio, C. Tsourakakis
ACM Transactions on Knowledge Discovery from Data (2022)
Dynamic Interventions for Networked Contagions
M. Papachristou, S. Banerjee, J. Kleinberg
Poster at EAAMO 2022 Conference (non-archival)
Measuring the Completeness of Economic Models
D. Fudenberg, J. Kleinberg, A. Liang, S. Mullainathan
Journal of Political Economy (2022)
Ordered Submodularity and its Applications to Diversifying Recommendations
J. Kleinberg, E. Ryu, E. Tardos
Preprint (2022)
Optimal stopping with behaviorally biased agents: The role of loss aversion and changing reference points
J. Kleinberg, R. Kleinberg, S. Oren
Games Econ. Behav. 133: 282-299 (2022)
Mechanisms for (Mis)allocating Scientific Credit
J. Kleinberg, S. Oren
Algorithmica 84(2): 344-378 (2022)
Four Years of FAccT: A Reflexive, Mixed-Methods Analysis of Research, Contributions, Shortcomings, and Future Prospects
Benjamin Laufer, Sameer Jain, A. Feder Cooper, Jon Kleinberg, and Hoda Heidari
Proc. 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2022)
Collective Obfuscation and Crowdsourcing
Benjamin Laufer and Niko Grupen
2022 KDD MIS2-TrueFact Workshop
End-to-end Auditing of Decision Pipelines
Benjamin Laufer, Emma Pierson, and Nikhil Garg
ICML workshop on Responsible Decision-Making in Dynamic Environments (RDMDE 2022)
Optimizing the order of actions in contact tracing
M. Meister and J. Kleinberg
Poster at EAAMO 2022 Conference (non-archival)
Digital security and reproductive rights: lessons for feminist cyberlaw
Michela Meister and Karen Levy
Quantifying Inequality in Underreported Medical Conditions
Divya Shanmugam and Emma Pierson
Preprint
Patients cannot consent to care unless they know how much it costs
Leah Pierson and Emma Pierson
British Medical Journal
No Rage Against the Machines: Threat of Automation Does Not Change Policy Preferences
Baobao Zhang
Proc. 5th AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES 2022)
Ethics and Governance of Artificial Intelligence: Evidence from a Survey of Machine Learning Researchers
Baobao Zhang, Markus Anderljung, Lauren Kahn, Noemi Dreksler, Michael C. Horowitz, and Allan Dafoe
Proc. 31st International Joint Conference on Artificial Intelligence (IJCAI 2022), Journal Track, Extended Abstract
2021
Designing Disaggregated Evaluations of AI Systems: Choices, Considerations, and Tradeoffs
Solon Barocas, Anhong Guo, Ece Kamar, Jacquelyn Krones, Meredith Ringel Morris, Jennifer Wortman Vaughan, Duncan Wadsworth, and Hanna Wallach
Proc. the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES 2021)
Representativeness in Statistics, Politics, and Machine Learning
Kyla Chasalow and Karen Levy
Proc. 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2021)
Hyperparameter Optimization Is Deceiving Us, and How to Stop It
A. Feder Cooper, Yucheng Lu, Jessica Zosa Forde, and Chris De Sa
Advances in Neural Information Processing Systems 34 (NeurIPS 2021)
Accuracy-Efficiency Trade-Offs and Accountability in Distributed ML Systems
Oral Presentation
A. Feder Cooper, Karen Levy, and Chris De Sa
Proc. 2021 ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO 2021)
Emergent Unfairness in Algorithmic Fairness-Accuracy Trade-Off Research
Oral Presentation
A. Feder Cooper and Ellen Abrams
Proc. 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES 2021)
Model Selection’s Disparate Impact in Real-World Deep Learning Applications
Contributed Talk
Jessica Zosa Forde*, A. Feder Cooper*, Kweku Kwegyir-Aggrey, Christopher De Sa, and Michael Littman
Workshop on the Science and Engineering of Deep Learning at ICLR 2021 (SEDL@ICLR 2021)
A National Program for Building Artificial Intelligence within Communities
Fernando A. Delgado
Federation of American Scientists (2021)
Sociotechnical Design in Legal Algorithmic Decision-Making
Fernando A. Delgado
Companion Publication of the ACM 2020 Conference on Computer Supported Cooperative Work and Social Computing (CSCW 2020 Companion)
Articulating a Community-Centered Research Agenda for AI Innovation Policy
Fernando A. Delgado and Karen Levy
Cornell Policy Review (2021)
Stakeholder Participation in AI: Beyond “Add Diverse Stakeholders and Stir”
Fernando A. Delgado, Stephen Yang, Michael Madaio, and Qian Yang
Workshop on Human-Centered AI at Conference on Neural Information Processing Systems (NeurIPS 2021)
Better Together?: How Externalities of Size Complicate Notions of Solidarity and Actuarial Fairness
Kate Donahue and Solon Barocas
Proc. 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2021)
Optimality and Stability in Federated Learning: A Game-theoretic Approach
Kate Donahue and Jon Kleinberg
Advances in Neural Information Processing Systems 34 (NeurIPS 2021)
Models of fairness in federated learning
Oral Presentation
Kate Donahue and Jon Kleinberg
NeurIPS Workshop on Learning and Decision-making with Strategic Feedback
Model-sharing Games: Analyzing Federated Learning Under Voluntary Participation
Kate Donahue and Jon Kleinberg
Proc. 35th AAAI Conference on Artificial Intelligence (AAAI 2021)
Computer Vision and Conflicting Values: Describing People with Automated Alt Text
Margot Hanley, Solon Barocas, Karen Levy, Shiri Azenkot, and Helen Nissenbaum
Proc. 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES 2021)
Allocating Opportunities in a Dynamic Model of Intergenerational Mobility
Best Paper (CS Category)
Hoda Heidari and Jon Kleinberg
Proc. 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT 2021)
On Modeling Human Perceptions of Allocation Policies with Uncertain Outcomes
Best Paper Award
Hoda Heidari, Solon Barocas, Jon Kleinberg, and Karen Levy
Proc. 2021 ACM Conference on Economics and Computation (EC 2021)
Was “science” on the ballot?
Stephen Hilgartner, J. Benjamin Hurlbut, and Sheila Jasanoff
Science, Vol. 371, Issue 6532 (2021)
Worlds Apart: Technology, Remote Work, and Equity
Aspen Russell and Eitan Frachtenberg
Computer (2021)
Random Graphs with Prescribed K-Core Sequences: A New Null Model for Network Analysis
Katherine Van Koevering, Austin R. Benson, and Jon Kleinberg
Proc. Web Conference 2021 (WWW 2021)
Algorithmic Auditing and Social Justice: Lessons from the History of Audit Studies
Oral Presentation
Briana Vecchione, Solon Barocas, and Karen Levy
Proc. 2021 ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO 2021)